
interning @ IRCC, developing fall detection models @ Fallyx, attending collision conf, & more!
Bi-Monthly Update: May & June 2024


Hey, I’m Dev, and if you’re new to my bi-monthly newsletter, welcome! My bi-monthly newsletter is a way to hold myself accountable of progress, but also a way for me to share insights / reflections & recap what’s been going on in my life. Allow me to quickly introduce myself, I’m a 3rd year computer science undergrad at the University of Toronto & a data scientist at IRCC. Over the last couple months I started my summer internship at IRCC, started working as a MLE at Fallyx, built out several machine learning projects, and more. Here is a quick tl;dr of what i was up to over the last 2 months:
Started my summer internship at IRCC
Developed ML models from scratch at Fallyx
Attended collision conf in Toronto
Researched into autoencoders & implemented them from scratch
wrote an article about them as well
Learnt about GANs (generative adversarial networks) & implemented them from scratch
wrote an article about this as well
Participated in a couple kaggle competitions :)
Started stanford’s deep learning course (cs230)
Documented my ML learning journey on twitter
These last couple months have been a real eye-opener. It’s like when you're free to do whatever, you end up showing what actually matters to you. funny how that works – your choices become a sort of mirror, reflecting your real priorities. with that being said, let’s jump into this newsletter!
interning at IRCC
During the course of these last couple months, I started my summer internship as a junior data scientist at the federal government, specifically working in the immigration & refugees department. I’ve had the chance to work on many different NLP models, specifically playing around with model performance with anonymized data. One of the most interesting aspects has been figuring out how to maintain model performance when dealing with redacted or anonymized text. It's a delicate balance – we need to protect individuals' privacy while still extracting meaningful insights from the data. I've learned various techniques for data masking and how to fine-tune models to work effectively with partially obscured information.

It’s hard to believe that half of my internship is already over, but it’s been a great learning experience so far. One of the most significant insights I've gained is the stark contrast between the mindset required for a professional data scientist versus model development for personal projects. The models I develop here are not mere academic exercises; they're destined for public use, which introduces a whole new level of responsibility. This reality has forced me to carefully consider the delicate balance between accuracy and efficiency – a concept that's reshaped my approach to problem-solving.
It was a big mindset shift since in my personal projects, I often prioritized accuracy above all else; it was always about optimizing for the least false positives / negatives, but this shift in perspective has been eye-opening. In my personal projects, I often found myself fixated on achieving the highest possible accuracy, sometimes at the expense of other factors. However, in a professional setting, I've come to appreciate that the most accurate model isn't always the most practical or impactful. It's about finding that sweet spot where reliability, efficiency, and accuracy converge to create real-world value.
Another insight I’ve come to appreciate is how crucial it is to be able to explain technical concepts to non-technical stakeholders in a way that's both accurate and accessible. I've also gained a deeper appreciation for the real-world impact of data science in shaping policy decisions. It's been eye-opening to see how the models we develop can potentially influence people's lives and opportunities. It's not enough to build a great model; you need to be able to convey its strengths, limitations, and implications to people who may not have a technical background. It goes back to the idea that “if you can’t explain it to a child, you don’t really understand what’s going on”. I've found myself regularly translating complex statistical concepts into plain language, using analogies and visualizations to bridge the gap between data science jargon and everyday understanding. Overall, it’s been a great learning experience and I can’t wait to see what the next 2 months have in stock for me :)
working at Fallyx as a MLE
During these past 2 months, I’ve also started working at Fallyx as a Machine Learning Engineer. To give some context, Fallyx is working on detecting & predicting falls in retirement homes using smart clothing. More specifically, using a sensor that captures a bunch of key data points which makes the classification process easier; these data points are passed through a couple ML models that I’ve developed to allow for accurate fall classification.
As I’ve been working in this role, I’ve had to pivot a bunch of times, from using online datasets to curating our own. This experience has been incredibly valuable, teaching me the importance of adaptability in real-world machine learning projects. I’ve grown to appreciate how important data is in ML models — in the past, I’ve used online datasets where everything is labelled and handed to me in perfect condition, but now, I’ve had to work with creating a custom dataset specifically catered to this problem. One of the most interesting aspects has been the iterative nature of this process. As we've collected more data and refined our models, we've uncovered new patterns and edge cases that we hadn't initially considered. This has led to several rounds of tweaking our model to capture these newly discovered scenarios which allows for accurate fall detection.

This role has also been a great opportunity to take everything I’ve learned so far in the Machine Learning space and apply it to a real-world problem with immediate and potentially life-saving impact. One of the key takeaways from this experience definitely has been the profound sense of purpose it's given me in my work. Every day, I'm reminded that the models I’m developing aren't just lines of code or statistical patterns – they're tools that could significantly improve the quality of life for seniors. It's incredibly fulfilling to know that my work might help prevent falls, giving elderly individuals more confidence to move freely and independently in their living spaces.
Moreover, working on this project has given me a greater appreciation for the intersection of technology and eldercare. It's exciting to be part of a movement that's leveraging cutting-edge AI to address one of the most pressing issues in aging populations. The potential to scale this technology and make a difference in the lives of seniors worldwide is really motivating; super excited to keep iterating on the models and making them better.
update on ML progress
Throughout the course of these last couple months, I’ve spent more time into learning about ML field, specifically the theoretical aspects of it. I realized that regardless of how much time I spend building models, if I’m unable to understand what’s going on behind the scenes, it’s pointless. Now that I’ve spent ~ 2 months just focusing on the theory, it’s been rewarding to see how this deeper understanding has changed my perspective on the models I work with. When I’m making a custom model architecture, it no longer feels like I’m guessing how many layers I should put or what activation function I should use or what loss function to use; they all feel like educated guesses which more often than not are correct.
To hold myself accountable, I started writing my updates on what I’m learning everyday on twitter. Posting what you do on a public platform is a powerful motivator. It's not just about showing off achievements; it's about creating a consistent habit of learning and sharing. This practice has pushed me to maintain a steady pace of learning, even on days when motivation was low. Moreover, documenting my learning journey has created a tangible record of my progress. Looking back at my earlier posts, I can see how far I've come in my understanding. It's a powerful reminder of the idea of compound growth; those small daily efforts really do add up over time. Looking back at my earlier posts, it's cool to see how much my understanding has deepened. Topics that used to confuse me now feel almost second nature.

During this ML learning process, I’ve been prioritizing taking what I learn and produce something tangible out of it. I’ve been watching a stanford lecture series (cs230), reading a bunch of deep learning & machine learning textbooks (little book of deep learning, dive into deep learning, etc.), reading research papers, etc. But reading / watching the content isn’t enough, I realized I needed to implement the concept from scratch to truly be able to understand it. As such, I've been implementing key algorithms and models from scratch. It's one thing to understand the theory behind backpropagation or convolutional neural networks, but actually coding them up brings a whole new level of insight. I've found that this approach often reveals gaps in my understanding that I might not have noticed otherwise. I’ve been writing my notes and implementations publically on my github, if you want to check it out, click the button below :) Along with all that, I’ve been writing a couple articles on full architectures which I’ve built from the ground up & participated in a kaggle competition as well!
GANs
I implemented GANs (generative adversarial networks) from scratch in python. To give some context, GANs are a type of generative model that involves two neural networks — the Generator and the Discriminator — competing against each other to create realistic data. This architecture is particularly effective in generating high-quality images and other types of data.

To give a more concrete example, one network generates new data by taking an input data sample and modifying it as much as possible. The other network tries to predict whether the generated data output belongs in the original dataset. In other words, the predicting network determines whether the generated data is fake or real. The system generates newer, improved versions of fake data values until the predicting network can no longer distinguish fake from original.
I wrote all about how this architecture works and how to implement it from the ground up, if you want to check out the article, click the link below :)
Autoencoders
I also implemented another deep learning architecture from scratch, this one is called an Autoencoder. It’s not that popular, but they hold immense potential and versatility in various domains. They excel at tasks such as data compression, image denoising, and feature extraction, making them a powerful tool for data scientists and engineers.
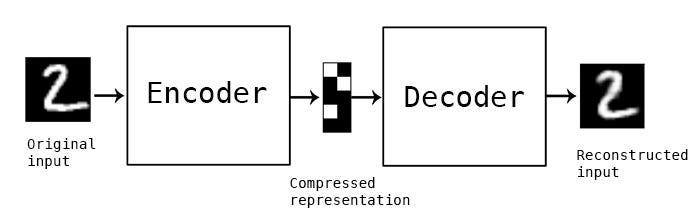
Autoencoders are a type of neural network, more specifically, they are a type of neural network that is trained to copy its input to the output. To express this in other words, suppose our autoencoder is defined by this function, f(x), then the output of our autoencoder would be as follows: f(x) = x. This is extremely helpful as it allows the Autoencoder neural network to be able to reconstruct things such as images, text, and other data from compressed versions of themselves.
I built the encoder architecture from scratch in the article & also used it to train on the MNIST dataset, check it out here :)
academic success kaggle competition
During this past month, I also spent some time trying to translate the theoretical knowledge I’ve gathered into a practical application. I’ve been working on a academic success kaggle competition — the end goal was to predict whether or not a student would graduate based on 30+ different features. This was a relatively simple competition, but it was a good baseline to take my knowledge of layers, activation functions, loss functions, etc. and apply it to an actual problem.

I was able to get the model to train at over 87% and I documented everything I did in my github, click the link below to check it out :)
If you’ve made it this far, I would like to thank you for taking time to read my newsletter. I hope that my insights and experiences have been valuable to you, and I look forward to sharing more of what I’m up to in the future. With that being said, here’s what I’m going to be working on in the next few months:
Continuing my work at IRCC as a data scientist intern
Working with Fallyx to develop Machine Learning models for fall detection
Bigger update to come on the next newsletter :)
Keeping up with writing — producing some articles in the ML space and explaining how important algorithms work
Developing some bigger full stack ML projects
That’s all from me; if you enjoyed reading this newsletter, please consider subscribing and I’ll see you in the next one 😅.