


building Tail-TrackR, participating in Canada's biggest hackathon, building in the ML space & more!
Bi-Monthly Update: September & October 2023


hey, I’m Dev, and if you’re new to my bi-monthly newsletter, welcome! My bi-monthly newsletter is where I recap what’s been going on in my life and share some thoughts and reflections from the last couple months in. Allow me to introduce myself, I’m currently a Machine Learning researcher, working in a Medical Imaging x AI lab under Dr. Tyrrell; looking to integrate Artificial Intelligence into a clinical setting to improve the diagnosis process. Over the course of these last 2 months, I’ve had the chance to work on numerous projects, produced content, and started my sophomore year! The general theme of these last 2 months have been transition and adaptation; I spent a lot of time over the course of these last 2 months trying to find my flow state and working on meaningful projects. Here is a quick tl;dr of what I did over the last 2 month!
Participated in Canada’s biggest Hackathon
Worked on a project under supervision of a professor @ UofT
Wrote an article about recent papers in the ML space
Working on a project to improve concentration levels with ML
Implemented ML algorithms from scratch
I spent a lot of my off time from university working on understanding fundamental concepts within the machine learning space, while also working towards solving genuine problems in the world. Now in typical newsletter fashion, let’s sit down and reflect on these last 2 months! Side note: if you would like to stay updated on my progress and what I’ve been up to, consider subscribing!
making a multimodal AI-model to help visually impaired individuals 👨🏽🦯
Earlier in September, I participated in Canada’s largest hackathon with over a 1000 hackers coming from all parts of the world. This was my first year participating in it and it honestly was a great experience — spending 36 hours and working on developing a comprehensive solution to an existing problem in modern day society was a fun, but challenging experience. The hackathon wasn’t restricted by a specific theme, we were given 36 hours to build something really cool → personally, I find these hackathons more engaging since we’re given a larger playing field to work with. More than that, we can adopt a problem-based approach instead of a solution based approach → it helps practice with better mental models to approach problems.
My group and I finalized on tackling the problem of helping visually impaired individuals navigating around crowded spaces. One of the biggest problems these individuals face is that it is extremely difficult for them to get from point A to B in packed areas. Imagine trying to navigate around a crowded mall with a blindfold, it’s nearly impossible. The current solution to this problem is a walking stick, but that can only do so much, especially with people constantly moving around; it becomes difficult to get a strong idea of your surroundings. So we decided to build a multimodel AI-model to help visually impaired individuals move around.
The program uses the user’s iPhone camera (ideally, this would be a set of glasses with a camera for ease of use) to scan their surroundings; sampling images every couple of seconds and passing them to the Detectron2 model. This model analyzes the image, performs object detection, and creates bounding boxes of the objects near the visually impaired individual. The bounding boxes are processed in the backend and converted into simple English descriptions (i.e. there is a chair on the left) by splitting the image into a grid with 5x5 pixel boxes. This English description is fed to Cohere’s LLM and the model provides an in-depth description of how to navigate/proceed forward. This description is fed to the individual in an audio format using Whisper from OpenAI.

If you want to learn more about the project and see our GitHub, check out our Devpost portfolio.
Overall, the entire experience was really great — had a ton of fun building with my group and meeting some cool people over the weekend. One thing that I took away from the entire experience was that diverse perspectives lead to better solutions. My hackathon team consisted of individuals that have different backgrounds and various skill sets; this diversity in the group brought fresh perspectives to the project, but also new approaches to tackle the problem. Another insight that was reinforced over the weekend was that you become the average of the people you spend the most time around. I realized that being around great engineers over the weekend pushed me to approach problems in ways that I hadn’t considered before → it was a note to my future self to surround myself with people who inspire me, challenge me, and make me better.
building TAIL-TrackR 🐾
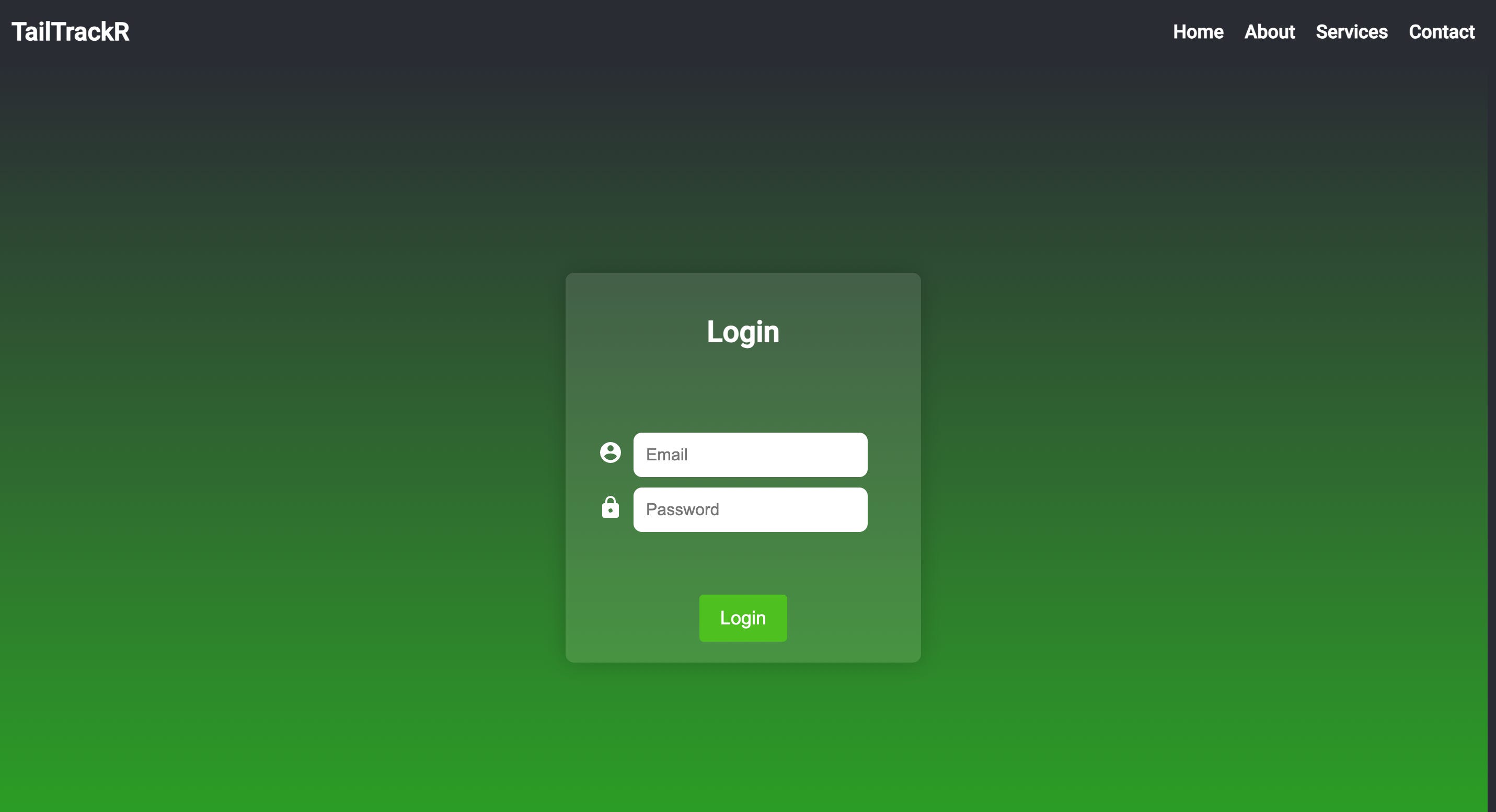
Along with the chaos that university brings, I’ve been working under the supervision of Professor Ashraf at UofT to build out a cool project that would benefit the community. A couple friends and I approached him with a project proposal that would solve a problem in our community at UofT → a common trend on our campus is that we have many animals roaming around, whether those be deers, foxes, geese, etc. And so, we proposed to build an application that matches up pet owners with their lost pets if they go missing. The status quo at the moment sucks; traditional methods of reuniting lost pets with their owners involves posting flyers, contacting local shelters, or posting on social media. None of these are nearly as effective, the pipeline of getting a lost animal to its owner is extremely disjoint and there isn’t a clear flow defined. As such, my group and I proposed Tail TrackR — an application that allows users to upload pictures of lost animals + where they were found into our app. From that point onwards, we have a ML back-end which classifies the animal and any significant features i.e the breed, colour, eye colour, etc. Once this is done, the nearest animal shelter is automatically contacted and this information is fed into their database. For the owner, they can simply login to the app and they can say they lost an animal that has certain features and if a similar animal enters our database, they will be notified.
Our goal was to improve the status quo by creating a pipeline that flows more freely → we want to reduce the number of places where something can go wrong. By having everything in one large database, it makes it easier to contact owners and animal shelters — in turn, this mitigates the risk of something going wrong in the chain of communication. As for progress, we’ve made some meaningful progress so far; we trained the ML model on the backend — we have 2 models working for 2 animals, dogs & cats. The model has super simple functionality at the moment, currently only identifies the breed of the cat / dog, but we’re working on extrapolating the functionality to include feature detection as well. Along with that, we’ve got our front-end figured out and here’s what it looks like as of right now:
This entire experience of working under a professor is refreshing in a sense; having someone who is constantly holding you accountable is a breath of fresh air. Being in extremely competitive academic environments or working on side projects by myself, there isn’t a guarantee of having someone to hold you accountable every single time. But here, it's different. It's like having a steady breeze at your back. There's something empowering about it. Accountability becomes this invisible force, pushing you forward even when the academic road gets bumpy. It's not just about meeting deadlines or ticking off tasks; it's this shared journey of growth. Knowing someone's got skin in the game, pushing you to outdo yourself — it's a motivation booster that's hard to replicate when you're flying solo. In these collaborative academic settings, accountability is more than a productivity hack. It's about bouncing ideas around, collectively chasing after knowledge, and realizing that your progress is woven into a bigger picture. I’ve realized that accountability isn’t just a tool for success; it's the guiding force that often shapes the whole learning experience. The experience so far has been great, but it’s only the start to this project; super excited to have a full fledged update in the next newsletter 😁
ML learning journey update
For those of you who know me well, I’ve been well-immersed in the ML space for some time and over the course of the last 2 months, I’ve spent time working on some side projects as well. I’ve tried to optimize my intake of knowledge by broadening the range of inputs from where I’m consuming information; reading textbooks, watching lectures from ML courses from Stanford, implementing model architectures from scratch, and reading up on the latest papers in the ML space. Having consumed knowledge from many different sources, it’s kind of neat to see how concepts at the lowest level can be extrapolated to ground-breaking research. I spent a good chunk of time working on implementing some foundational papers in the ML space and training them on test data to get a better grasp of the theoretical concepts. Worked on 2 main concepts, autoencoders and linear regression.
autoencoders
To give some background, autoencoders are a subset of neural networks designed for unsupervised learning. The core idea revolves around training the network to encode input data into a compact representation and then decode it back to its original form. In simple words, this basically means taking the input data, breaking it down into its simplest form, getting rid of the not so important information, and then reconstructing the input. This process not only enables data compression but also facilitates the extraction of essential features or patterns inherent in the input.
![Autoencoders in Deep Learning: Tutorial & Use Cases [2023]](https://substackcdn.com/image/fetch/$s_!cj2N!,f_auto,q_auto:good,fl_progressive:steep/https%3A%2F%2Fsubstack-post-media.s3.amazonaws.com%2Fpublic%2Fimages%2F062c8c2a-af76-4076-b47b-3d068f2f76be_1240x752.png "Autoencoders in Deep Learning: Tutorial & Use Cases [2023]")
One of the key components of autoencoders is the bottleneck layer, also known as the latent space. This layer forces the network to learn a condensed representation of the input, emphasizing the most critical information while discarding non-essential details. At first, it felt like autoencoders didn’t do anything useful, having a model that outputs the input felt a bit redundant at first, but it’s applications are actually pretty cool.
The applications of autoencoders extend far beyond mere data compression. One intriguing aspect is their ability to denoise data, where the network learns to reconstruct clean versions of corrupted input. This process involves training the autoencoder on noisy data and observing how it adeptly filters out the unwanted elements during reconstruction. The implications for real-world applications, such as image restoration or signal processing, became increasingly evident as I experimented with different datasets. Furthermore, autoencoders play a pivotal role in anomaly detection. By training the network on normal data patterns, it becomes proficient at reconstructing typical instances. Anomalies, being deviations from these learned patterns, result in reconstruction errors that can be easily detected. This application has promising implications across various domains, from cybersecurity to quality control in manufacturing.
I reimplemented the entire architecture from scratch, click the github link below if you want to check out the implementation → I implemented it in python using tensorflow! If you’re interested in the original paper, here’s the link.
linear regression 📈
The other ML concept that I implemented from scratch was linear regression; although it’s more on the simple side, I wanted to spend some time going back to the math and implementing the math behind linear regression from scratch. So, I decided to take a step back from the glitz and glamour of deep learning and spent some quality time revisiting the roots with linear regression. It might not be the star of the show, but there's something oddly satisfying about getting into the nitty-gritty of the math.
Linear regression is the simplest form of prediction, the equation is in the form of y = m*x + b and we only have to worry about 2 variables, x and y. Now, when it comes to implementing linear regression, one of the key components is the cost function, often represented by the Mean Squared Error (MSE). This function measures the average squared difference between the predicted values and the actual values. The goal during the training process is to minimize this cost function.
To achieve this minimization, gradient descent comes into play. Gradient descent is an optimization algorithm that adjusts the parameters of the model iteratively to find the minimum of the cost function. It works by calculating the gradient of the cost function with respect to the parameters and moving in the opposite direction of the gradient.

In the context of linear regression, the parameters m and b are adjusted in the direction that reduces the MSE. This process is repeated until the algorithm converges to a set of parameters that result in the minimum possible cost. That was a lot of math, but the image above summarizes everything in a more readable form! If you want to check out the implementation, click the button below for the github repo where I implemented it all!
understanding sycophancy in LLMs 📑
The final part of my dive into ML was an article that I wrote. The article was about how sycophancy is slowly, but gradually creeping into Large Language Models. LLMs have been at the center of attention in the Machine Learning space ever since openAI released chatGPT to the public. Despite the excitement and hype behind this field, LLMs aren’t without their challenges and controversies. One pressing issue that has emerged is sycophancy within LLMs. Sycophancy refers to the inclination of these models to generate responses that excessively flatter individuals, organizations, or entities, often in an exaggerated or insincere manner. The introduction of sycophany in the LLM space raises ethical concerns, as it has the potential to spread false information, reinforce biases, and contribute to the creation of unethical or biased content. Recently, a paper has been published in this space, talking about potential ways to tackle this.

To solve this issue, the LLM was trained on synthetic data to prevent the large language model answering questions incorrectly. The premise of the approach is to address and mitigate a model’s inclination toward sycophancy by introducing a straightforward synthetic-data intervention during the fine-tuning process. This intervention involves training models on prompts where the truthfulness of a claim remains independent of the user’s opinion. The final results were actually quite promising and showed an increase in accuracy / precision. If you want to read more about it, check out the article by clicking the button below!
looking ahead.
If you’ve made it this far, I would like to thank you for taking time to read my newsletter. I hope that my insights and experiences have been valuable to you, and I look forward to sharing more of what I’m up to in the future. With that being said, here’s what I’m going to be working on in the next few months:
Finishing up Tail-TrackR
Getting back on the research grind at the lab
Keeping up with writing — I’m going to continue to consistently put out articles and pieces of writing.
That’s all from me; if you enjoyed reading this newsletter, please consider subscribing and I’ll see you in the next one 😅.